Eine der Schlüsselkomponenten eines jeden datenwissenschaftlichen Projekts ist die explorative Datenanalyse (EDA). Sie bildet häufig den ersten wichtigen Teil, bevor man sich im nächsten Schritt um die Modellierung der Daten und die Anwendung von Machine Learning-Modellen kümmert. In der EDA werden die wichtigsten Fragen zu den eigenen Daten beantwortet: Wie viele Beobachtungen und Variablen gibt es? Wie sieht die Struktur des Datensatzes aus? Gibt es fehlende oder duplizierte Werte? Eine gute Datenanalyse sorgt dafür, dass es bei der nachfolgenden Modellierung nicht plötzlich zu Überraschungen kommt.
Die explorative Analyse von Daten ist ein iterativer Prozess. Zunächst werden Fragen an den Datensatz gestellt, für die im nächsten Schritt durch die Visualisierung, Transformation und Modellierung der Daten Antworten gesucht werden müssen. Aus den Erkenntnissen dieses Schrittes können dann anschließend neue Fragen formuliert oder die ursprüngliche Fragestellung verfeinert werden. Man sollte sich bewusst sein, dass eine EDA kein formaler Prozess mit strengem Regelwerk ist. In der Anfangsphase sollte allen Ideen nachgegangen werden, auch wenn manche davon in einer Sackgasse enden werden. Unabhängig davon sollte das Ziel einer EDA immer sein, ein besseres Verständnis von den vorliegenden Daten zu bekommen.
Je nach Umfang des Datensatzes kann eine EDA zeitaufwändig sein, besonders wenn aufgrund einer großen Anzahl von Variablen im Datensatz das Erstellen von Darstellungen oder Gruppen von Darstellungen viel Code erfordert. Des Weiteren kommt man in der modernen Arbeitswelt häufig nicht darum herum, die Erkenntnisse aus den Analysen mit anderen zu teilen. Besonders wenn diese Personen keinen statistischen, mathematischen oder informatischen Hintergrund haben, ist es wichtig die Ergebnisse auf eine verständliche und visuell ansprechende Art aufzubereiten. Hierfür gibt es neben recht teuren Softwarelösungen wie QlikView oder Tableau von RStudio auch eine kostenfreie Lösung – R Shiny.
R Shiny ist ein Package für die freie Programmiersprache R, mit dessen Hilfe man interaktive Webapplikationen oder Dashboards erstellen und dabei im Backend auf den vollen Funktionsumfang aller R Packages zugreifen kann. R Shiny bietet dabei die Möglichkeit Analysen auf interaktive Weise mit anderen zu teilen.
Was die Erstellung von Applikationen und Dashboards mit R Shiny noch leichter macht, ist das zunächst keine CSS, JavaScript oder HTML benötigt werden. Des Weiteren bietet Shiny eine automatische reaktive Bindung zwischen In- und Outputs, was bedeutet, dass die App sich automatisch updaten kann, wenn der User beispielsweise eine Veränderung der Inputparameter in der Benutzeroberfläche vornimmt. Die vielen vorgefertigten Widgets erlauben es dem Nutzer außerdem leicht elegante und leistungsstarke Applikationen mit minimalem Aufwand zu programmieren.
Eine Shiny Applikation kann vereinfacht betrachtet in zwei Teile aufgeteilt werden:
UI.R
In diesem Teilscript wird die Benutzeroberfläche der Shiny App definiert, über die der User mit der App interagieren kann. Benutzerinputs werden hier aufgenommen und dynamisch Outputs, wie Tabellen oder Visualisierungen der Daten in Form von Graphen, erstellt.
Die Abbildung zeigt ein simples Beispiel für UI.R. Hier wird die Benutzeroberfläche der Applikation definiert. 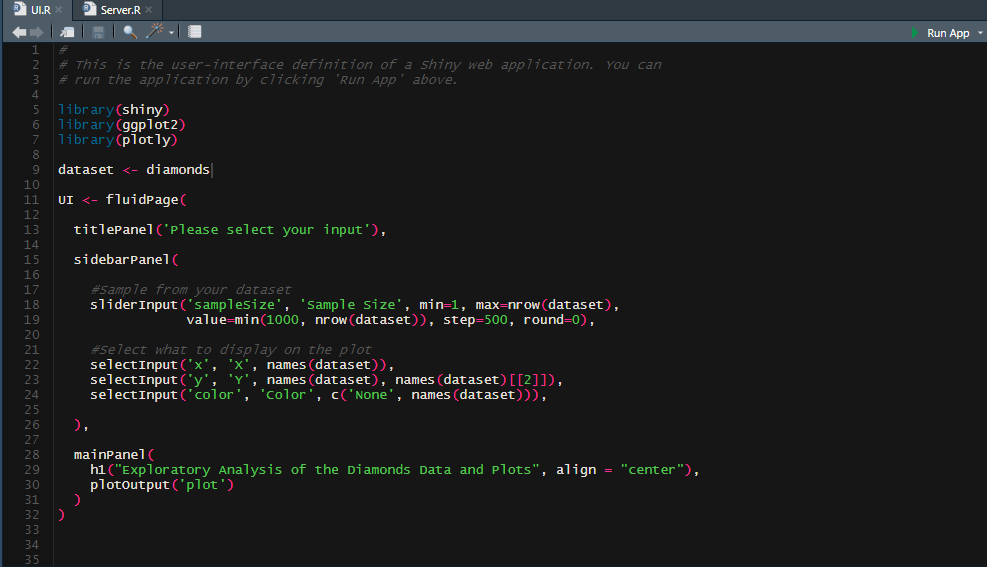
Server.R
Das Gehirn der Applikation sitzt in der Server.R Datei. In diesem Teil der App wird der Benutzerinput in den gewünschten Output übersetzt. Setzt der User beispielsweise Filter, die den Datensatz betreffen, werden diese im Serverskript auf den Datensatz angewendet und entsprechend Graphen neu kalkuliert.
Die Abbildung zeigt ein simples Beispiel für Server.R. Hier wird der Userinput in den entsprechenden Output übersetzt und beispielsweise Berechnungen dynamisch am Datensatz vorgenommen. 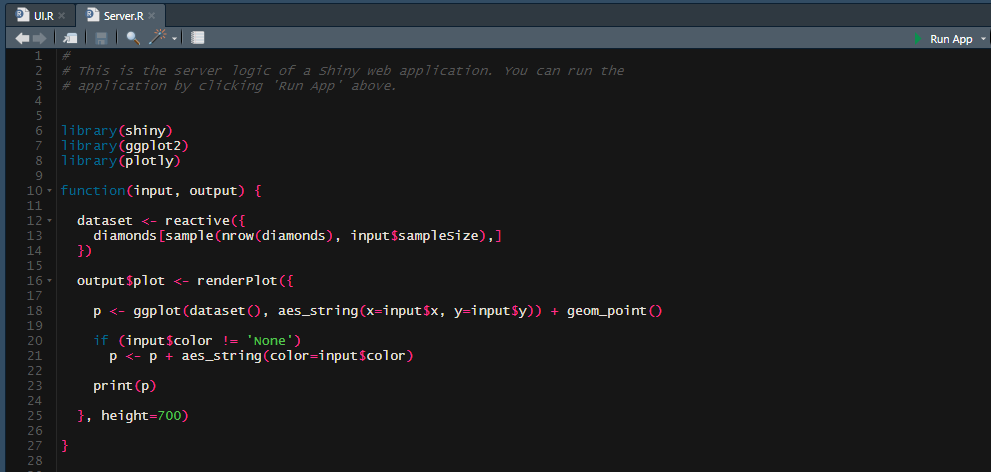
Durch einen einfachen Klick auf ‚Run App‘ in der RStudio-Oberfläche kann die Shiny Applikation lokal gestartet werden. Oftmals auf der linken Seite der Applikation befindet sich ein Bereich, in dem der Benutzer beispielsweise den zu betrachtenden Datensatz ändern (z. B. Datensatz) oder bestimmte Filter setzen kann. Möchte man für eine erste EDA beispielsweise die Zusammenhänge verschiedener Parameter im Datensatz verstehen, wie hier in Abbildung 3 den Zusammenhang zwischen Preis und Karatzahl, lassen sich in wenigen Zeilen Code und mithilfe von Shiny leicht verschiedene Variationen an Streudiagrammen erstellen. Durch die Vielzahl an R Visualisierungspaketen, die mit Shiny zusammenarbeiten können (ggplot, plotly u. a.), sind der visuellen Analyse von Daten hier keine Grenzen gesetzt.
Die Abbildung zeigt die Benutzeroberfläche einer einfachen Shiny Applikation.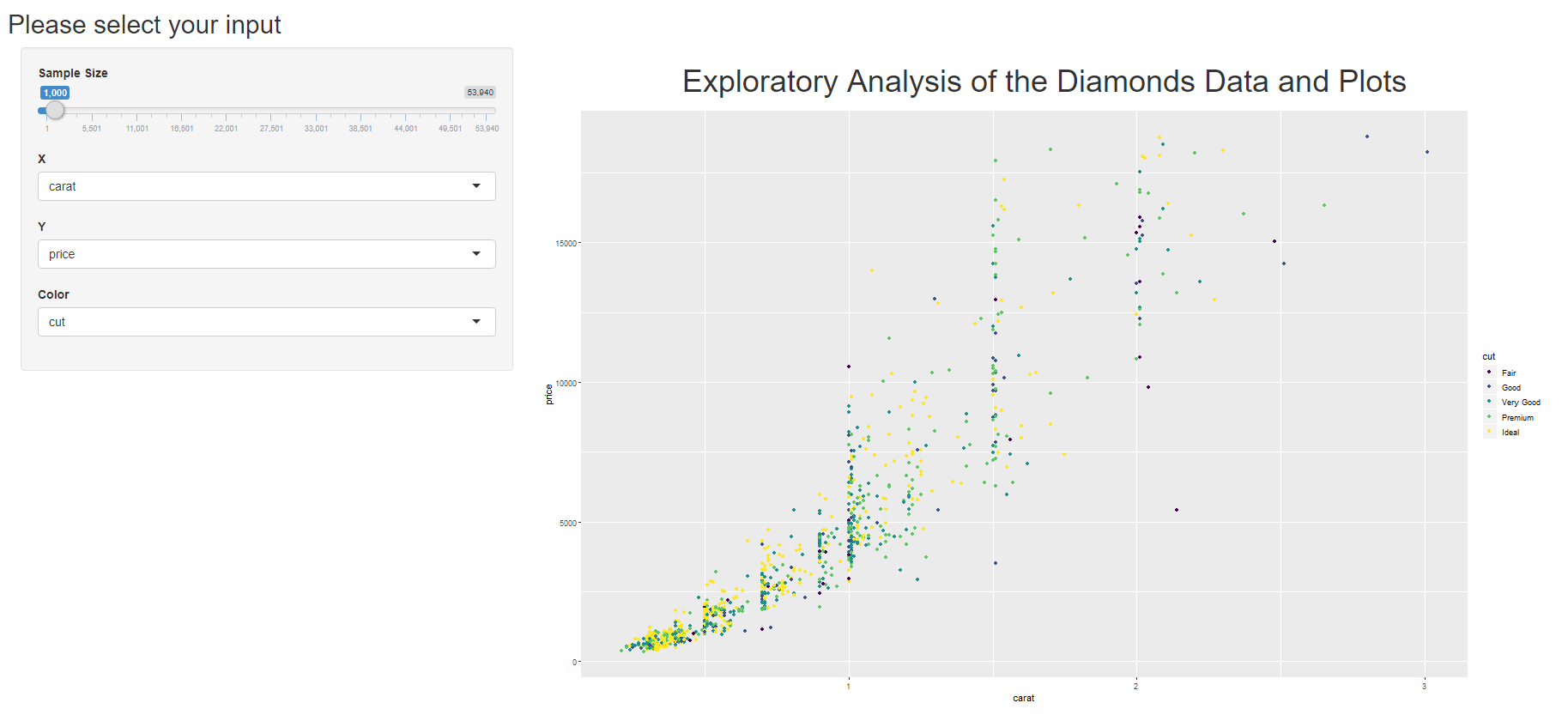
R Shiny birgt gegenüber anderen Datenvisualisierungstools noch weitere Vorteile: Zum einen ist das R Shiny Package Open Source, daher für jeden frei zugänglich und zunächst kostenfrei. Besteht jedoch der Wunsch die Applikation auf einen Shiny Server zu hosten, bieten Dienste wie shinyapps.io die Möglichkeit, die eigenen Apps sicher und kosteneffizient zu hosten. Zum anderen ist es mit Shiny möglich, selbst große Mengen an komplexen Daten zu visualisieren und hat dabei eine vergleichsweise kurze Reaktionszeit. Aufgrund dieser Eigenschaften ist R Shiny perfekt geeignet für die explorative Analyse von (großen) Datenmengen. Durch die Interaktivität von Shiny Apps ist es möglich, die verschiedenen Seiten eines Datensatzes in kurzer Zeit zu beleuchten und dabei Auffälligkeiten zu identifizieren. Zusätzlich erleichtern Shiny Apps die Kommunikation der Analyseergebnisse und ermöglichen, auch Menschen ohne Erfahrungen in der EDA einen visuell aufbereiteten Einstieg in die Daten.
Thema: Data Science, Machine Learning, Deep Learning, Datenanalyse, Advanced Analytics, R